|
|
6 years ago | |
|---|---|---|
| src/app | 6 years ago | |
| README.md | 6 years ago | |
README.md
About
mucc is a tool for processing data recovered by scalpel. It's features include:
- Splitting PDF files into sub-files.
- Deleting duplicate files, which can be used independently.
How it Works
Retrieving Sub-Files
scalpel parses disk images for %PDF headers and %EOF footers. If max_filsize is set high, the generated files will often consist of several concatenated sub-files. Here mucc finds the nested %PDF and %EOF tags and returns the files with byte sized precision.
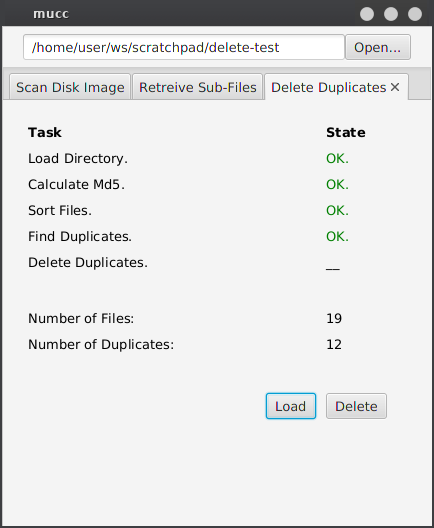
Deleting Duplicates
Here mucc calculates the md5 hash of each file and deletes the identical files.
Contents of src/app
| Class | Description |
|---|---|
| Artifacts | Simple objects used by other classes. |
| Controller | JavaFX class containing application logic. |
| Execute | Issues shell commands. |
| layout.fxml | Contains layout data. |
| Main | Main JavaFX class. Run from here. |
| QuicksortMd5 | Quicksort algorithm. |
| routines | Contains higher level routines called by Controller. |
| Tools | Simple tools used by other classes. |
| Write | Writes to /tmp. Used for data storage. |
Issues and Features
- Fix issues where nested duplicates would not be deleted on first pass.
- Make code prettier.
- Add scalpel integration.
- Replace "__" with progress indicators for states.
Screenshot